对互连带宽的永无止境的需求是塑造数据中心发展的关键趋势之一,其驱动力来自互联网流量的持续增长和人工智能大型语言模型的快速扩展。然而,带宽的提升通常意味着功耗的增加,这在数据中心能耗飙升的时代无疑是一个令人不快的副作用:值得注意的是,预计到2027年,一个英伟达机架的功耗将高达600千瓦。正因如此,业界正在寻求以皮焦耳/比特为单位的更高数据传输能效。
在这种情况下,共封装光器件(CPO)正迅速发展,主要成为网络交换机(数据中心横向扩展)中传统可插拔光模块的替代方案。通过将电子芯片和硅光子芯片集成在同一封装中,CPO 将光纤尽可能靠近 ASIC 或 FPGA,从而显著降低功耗并带来其他优势。本文将简要概述 CPO,并回顾该领域的一些最新进展。
CPO是必经之路
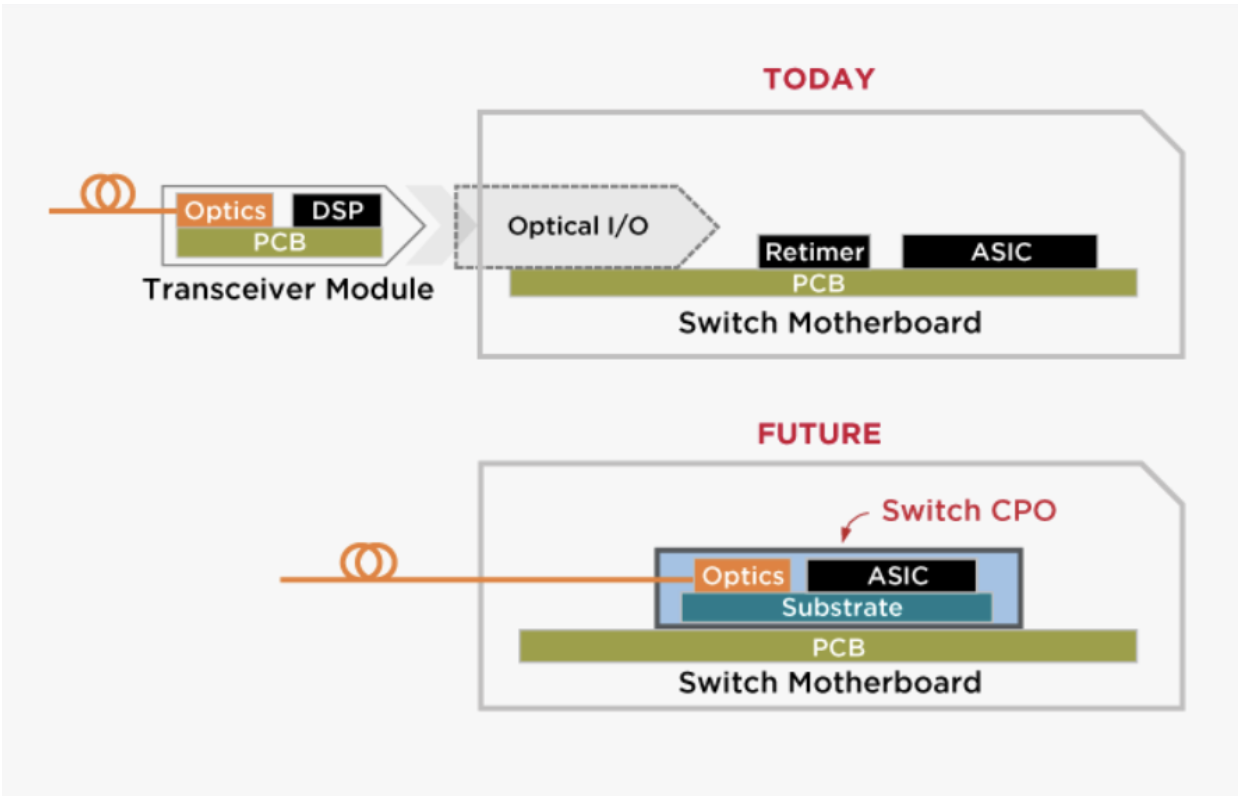
一般来说,数据中心内部互连的能源效率可以通过尽可能用光纤替代铜线来实现。然而,这种替代的实际可行性以及最终获得的收益不仅取决于传输速度和距离,还取决于许多其他因素。理想情况下,光纤应直接连接到网络交换机核心的硅芯片(ASIC 或FPGA),以避免铜缆混合互连的缺点。即使是相对较短的铜线,例如连接 ASIC/FPGA 和交换机前面板的 PCB 走线,也会造成信号损耗,并对信号完整性产生负面影响。
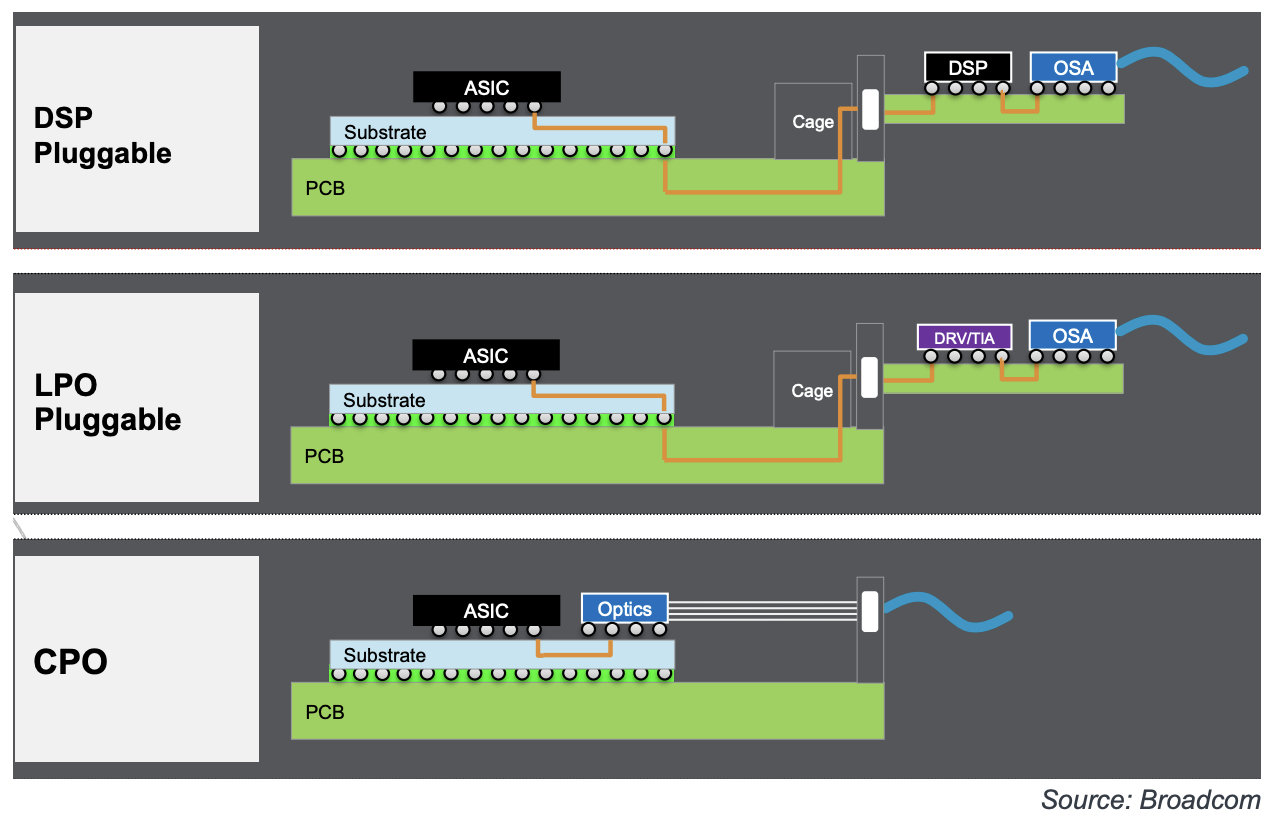
这需要耗电量巨大的基于DSP的重定时器和纠错电路,这会降低整体能效并增加延迟。但是,要将多根光纤尽可能靠近ASIC或FPGA,需要复杂的封装技术和连接器,而且由于板级或机架级的限制(例如空间限制或散热要求),实现起来也可能很困难。因此,迄今为止,大多数网络交换机都采用可插拔光模块,这意味着光纤仅延伸到前面板,仍然使用铜线(PCB走线)来连接前面板和ASIC或FPGA。
尽管面临诸多挑战,但过去几年中,CPO(互连封装)的优势日益凸显,这主要归因于两个原因。一方面,由于传输速度的提高、前面板连接密度的增加以及提高电源效率的迫切需求,数据中心互连的要求也越来越高。另一方面,得益于器件小型化(摩尔定律)和芯片组趋势推动的2.5D-3D封装技术的不断进步,CPO解决方案也得到了改进。
通过将电子芯片和硅光子芯片封装在同一封装内,CPO 技术相比可插拔模块具有多项优势。例如,电路板上通往前面板的损耗较大的铜线被低损耗光纤所取代;通常用于 25G/通道以上速率的两个高功耗 DSP 中的一个可以被移除,从而降低功耗和成本;更少的 DSP 和更长铜线的移除可以实现更高的带宽和更低的延迟;摆脱笨重的可插拔模块可以提高前面板的连接密度,和/或释放面板面积以改善散热。
据博通公司(Broadcom)称,作为该技术投入最深的公司之一,CPO 技术可以节省 30% 的功耗,降低 40% 的每比特光器件成本,并实现 1 Tbps/mm 的带宽密度。可插拔模块在可维护性方面可能仍然具有优势,因为它们易于更换。然而,由于光链路中最容易出现故障的组件是激光源,许多 CPO 解决方案通过采用可插拔激光源来解决可维护性问题。
巨头纷纷投身其中
过去几年,许多公司——无论规模大小——都押注CPO市场前景光明,纷纷涌入这一领域。举例来说,让我们快速浏览一下该领域一些主要参与者的产品和服务以及近期发布的公告。
博通的产品系列包括 25.6 Tbps 的 Humboldt CPO 交换机器件和 51.2 Tbps 的 CPO 以太网交换机Bailly,后者于 2024 年 3 月推出。据该公司称,与可插拔收发器解决方案相比,Bailly 可使光互连的功耗降低 70%,并且硅面积效率提高 8 倍。
2025年1月,Marvell宣布将CPO技术集成到定制AI加速器中。该方案基于Marvell于2023年12月发布的6.4 Tbps 3D SiPho引擎,该引擎已在2024年光纤通信大会暨展览会(OFC)上首次亮相。3D SiPho引擎将数百个组件(包括驱动器、跨阻放大器、调制器等)集成到一个芯片中,该芯片本身也成为XPU的一部分。
思科在2023年光纤通信展(OFC 2023)上展示了其CPO解决方案的优势,通过并排比较传统路由器(配备可插拔光模块)和搭载共封装硅光子学光纤模块的CPO路由器的实际功耗降低情况。不断扩展的CPO生态系统还包括康宁等主要光纤供应商。康宁在2025年OFC上展示了其CPO FlexConnect光纤,这是一种新型单模、抗弯曲光纤,专为短距离共封装光器件而优化。
近来,随着台积电和英伟达这两大巨头的加入,CPO(共封装光学)技术获得了进一步的发展动力。总部位于台湾的台积电在该领域拥有得天独厚的优势,有望发挥关键作用:正如我们所见,CPO 需要极致的器件小型化和先进的 2.5D-3D 封装技术,而这家全球领先的晶圆代工厂在这两方面都表现出色。在 2024 年技术研讨会上,台积电发布了名为 COUPE(紧凑型通用光子引擎)的硅光子解决方案,该公司将利用该方案开发 CPO 技术。台积电计划于 2026 年将 COUPE 集成到其 CoWoS 封装技术的基板上,实现功耗降低 2 倍、延迟降低 10 倍。该公司还在探索一种更先进的共封装光学方案,该方案将 COUPE 集成到 CoWoS 中介层上,预计功耗将进一步降低 5 倍,延迟将降低 2 倍。
至于英伟达,其首席执行官黄仁勋在2025年GTC大会上宣布,在其即将推出的网络交换机中采用CPO技术是其创新举措之一。除了将CPO解决方案视为满足AI数据中心极端横向扩展需求的一种方式外,英伟达还推出了一项重要的技术创新,即使用微环调制器代替马赫-曾德尔调制器,以实现更高的密度。英伟达声称,与传统网络相比,其CPO创新可提供3.5倍的更高能效、10倍的网络弹性以及1.3倍的更快部署速度。该公司将使用CPO技术构建其全新的Quantum-X和Spectrum-X硅光子网络交换机,这两款交换机将分别于今年晚些时候和2026年上市。 Nvidia 与包括台积电、Browave、相干公司、康宁公司、Fabrinet、富士康、Lumentum、Senko、SPIL、住友电工和 TFC Communication 在内的合作伙伴生态系统合作开发了其 CPO 解决方案。
最新进展和预测
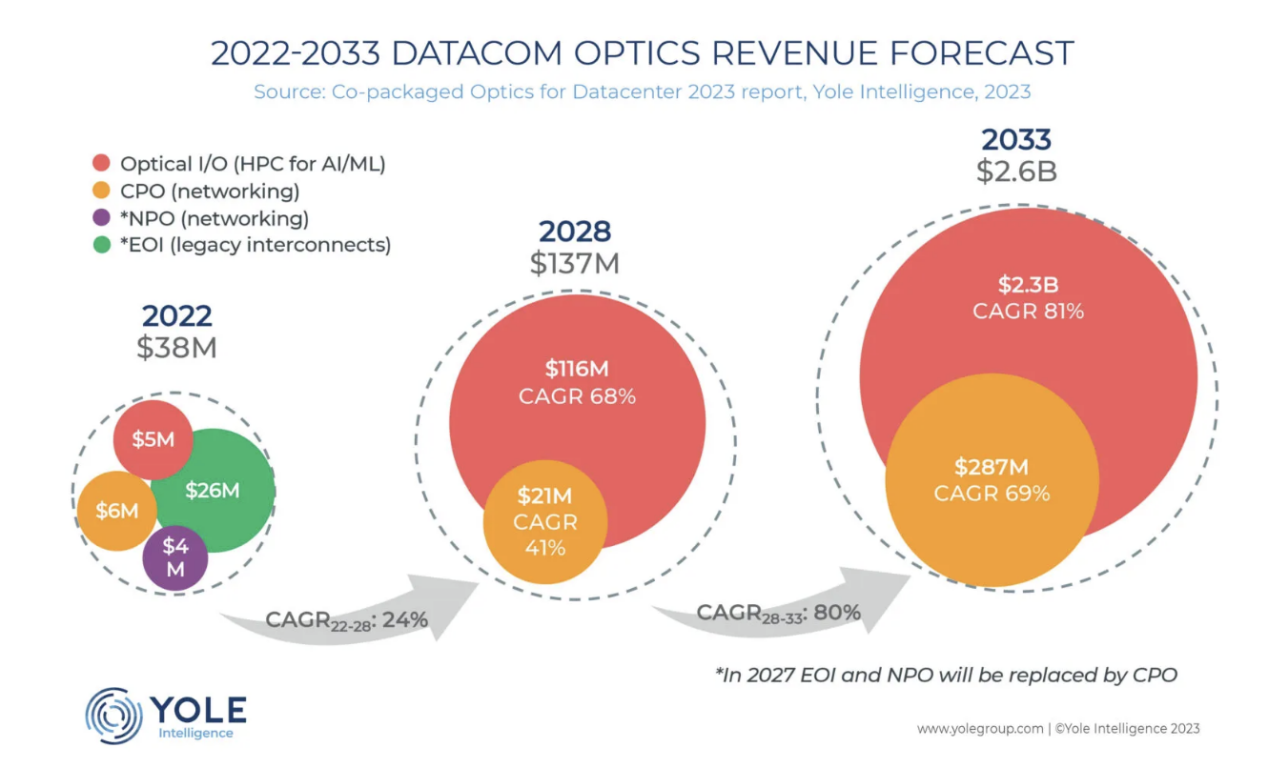
尽管目前备受关注,但CPO解决方案仍在不断发展,分析师认为,其在标准化、可制造性和测试等多个方面仍需改进。即便如此,目前规模较小的CPO市场势必会增长。根据Yole Group的数据,CPO市场在2022年的收入约为3800万美元,预计到2033年将达到26亿美元,2022年至2033年的复合年增长率(CAGR)为46%。
在八月份的一场会议上,LightCounting也对CPO的发展做出了预测。
LightCounting表示,目前,CPO 的研发活动正处于历史最高水平,预计 2027 年将实现大规模部署。LPO 的部署现已开始,明年将部署数百万个 LPO 模块(在 LPO 预测中包含了半时序 (LRO) 模块)。时序重整的可插拔模块不会消失——从 2025 年到 2030 年,800G 及更高速度收发器的出货量将增长两倍。
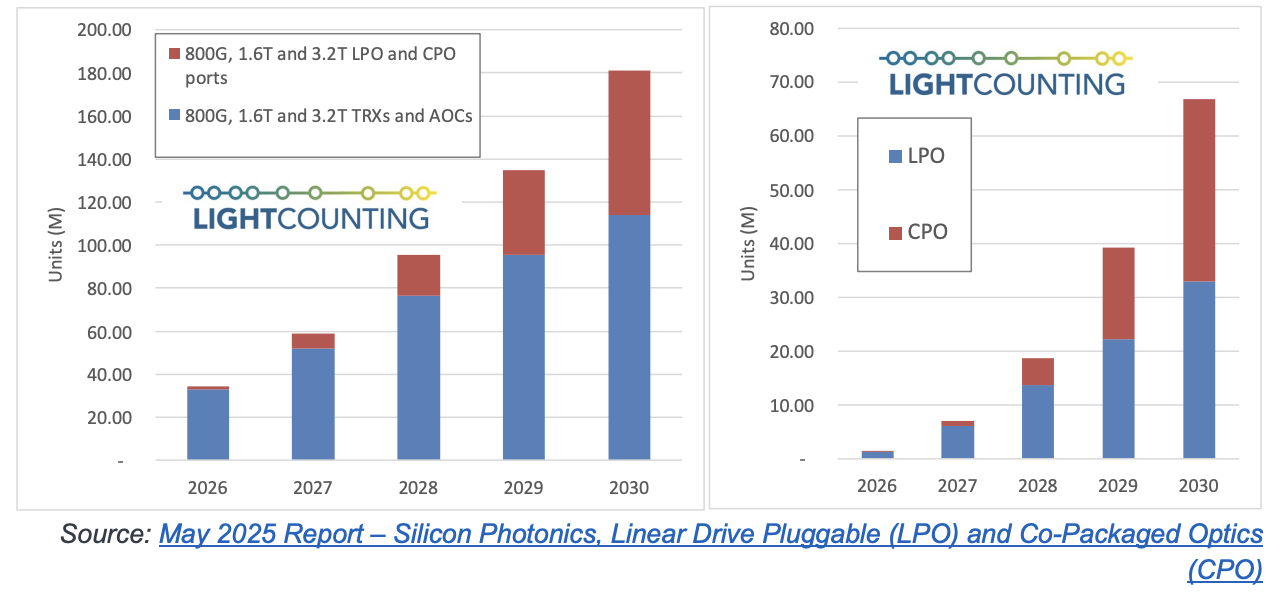
LightCounting 去年底上调了 CPO 的预测,以反映其在scale-up 网络中的未来应用。目前,博通和英伟达已将 CPO 应用于以太网和 InfiniBand 交换机,用于scale-up 网络。我们预计英伟达将在其未来的 NVLink 交换机版本中使用 CPO。
博通近期发布了专为横向扩展网络设计的 Tomahawk Ultra 交换机,LightCounting 预计该产品很快也将采用 CPO 技术。这是一款每通道 100G 的交换机,是博通成熟的 CPO 设计。
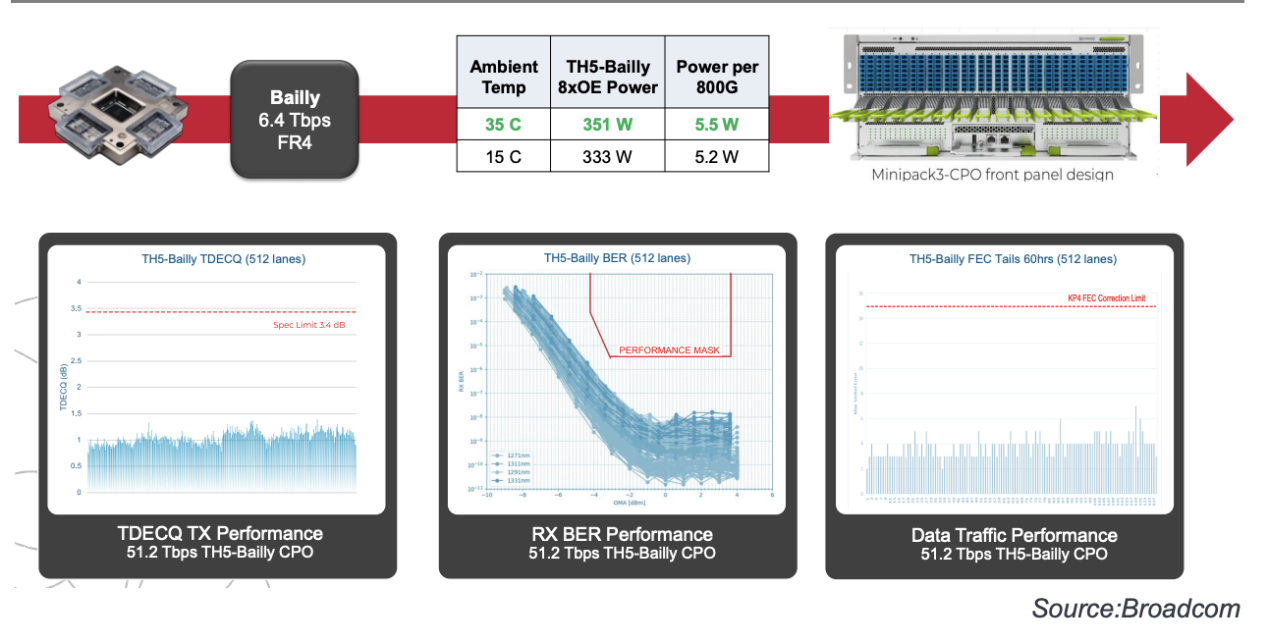
博通公司的 Anand Ramaswamy 介绍了 CPO 的最新数据。截至 2025 年 7 月 7 日,CPO 已累计完成超过 86,000 小时的 HTOL 压力测试。该测试包括 10 个机架单元和 13 张配备多个 CPO 端口的 Mezz 卡。这些测试数据相当于 800G CPO 端口 550 万小时的运行时间。测试还显示,CPO 在“FEC tails”方面性能极其稳定,在 1,200 小时内未出现链路抖动。虽然该指标通常不用于表征可插拔光模块的性能,但对于大规模网络中的连接至关重要。
下图总结了博通 CPO 的性能,表明其在各项参数上均表现出较大的裕量。此外,在 35°C 的温度下,每个端口的功耗也非常稳定,为 5.5W。
Coherent 公司的 Vipul Bhatt 指出,CPO 和可插拔收发器针对的是两个需求不同的市场,如图 4 所示。高性能插座可以弥合需求上的差距,为 CPO 和共封装铜 (CPC) 连接提供选择,从而支持可插拔光器件。
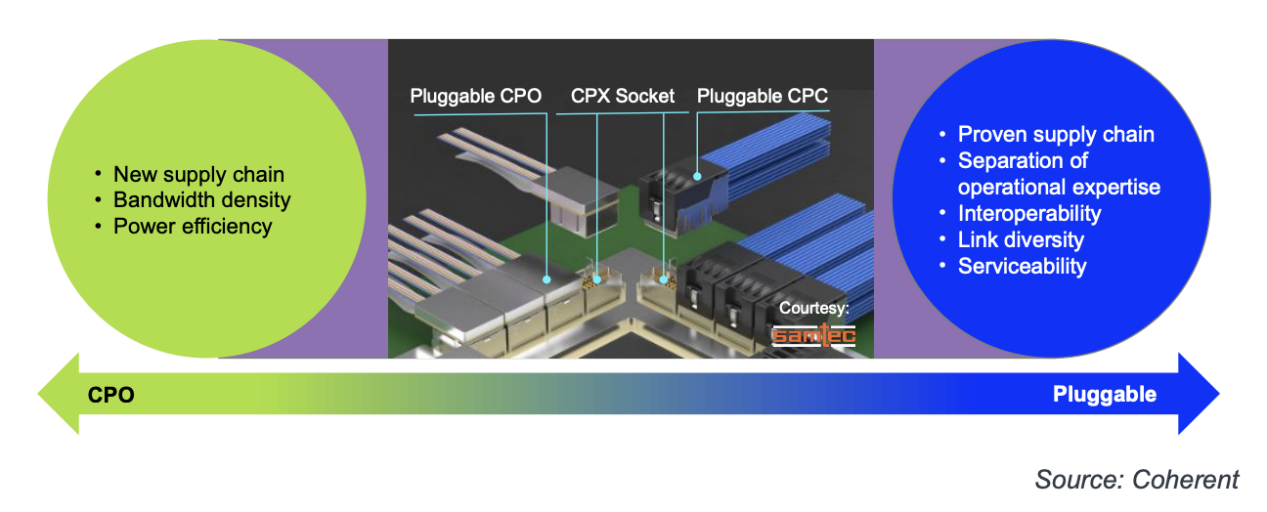
博通和英伟达目前的CPO设计采用不可插拔(焊接式)CPO引擎,以降低交换机ASIC和CPO之间的电气损耗。可插拔CPO虽然会额外带来1 dB的损耗,但这将使CPO市场更加开放竞争,类似于目前可插拔收发器的生态系统。包括Meta和微软在内的主要客户都倡导建立这样的生态系统,领先的CPO供应商迟早会接受这一要求,将其作为大规模部署的必要条件。
Vipul还列出了CPO所需的众多产品,无论其是否可插拔,如下图所示。

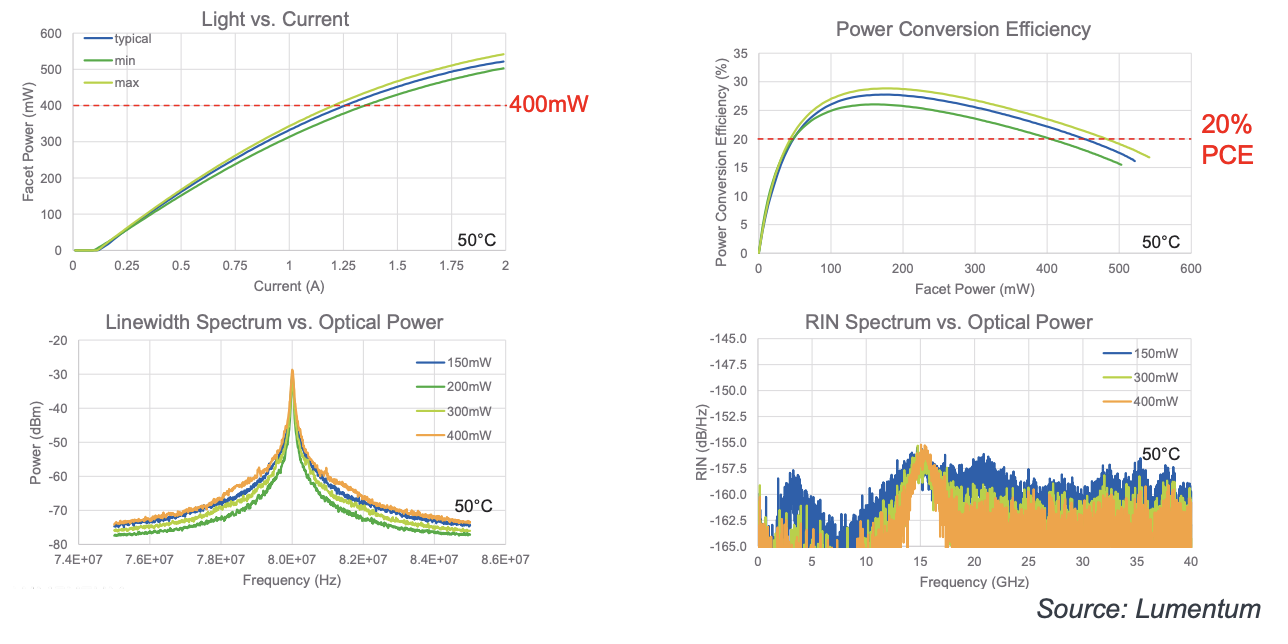
Lumentum 公司的 Matt Sysak 展示了用于 CPO 的外部激光源 (ELS) 中的高功率 CW 激光器的性能数据,如图所示。该高功率激光芯片的设计基于 Lumentum 公司数十年来在用于 EDFA 的高功率激光器方面的创新。
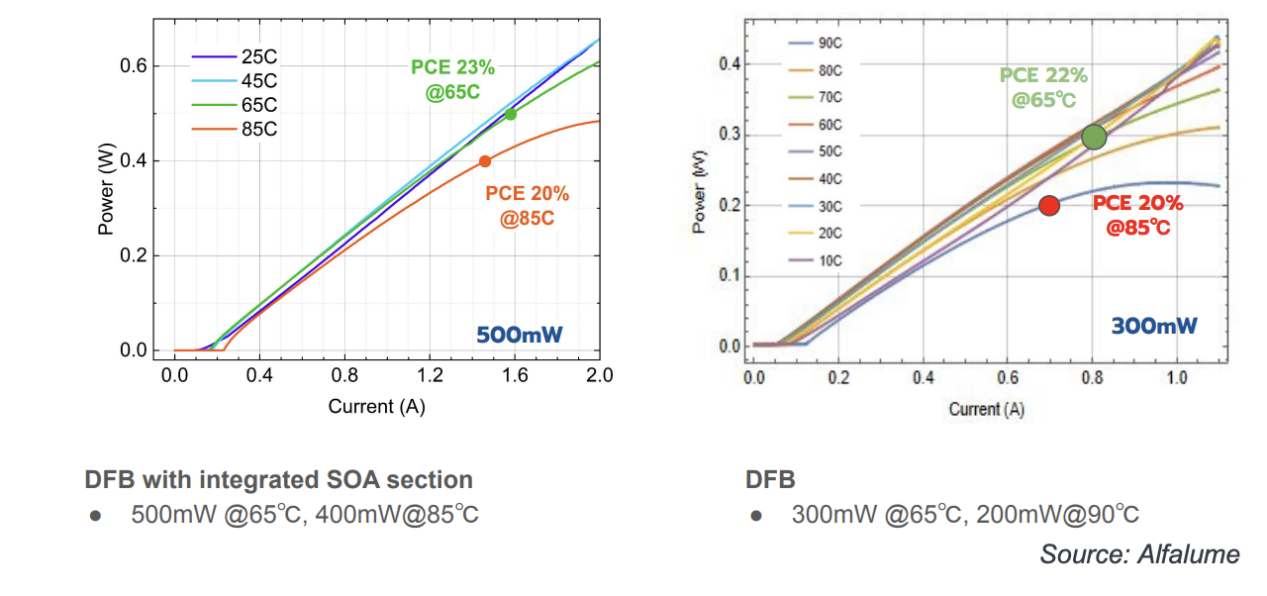
Alfalume公司的Alexey Kovsh分享了量子点(QD)激光器的最新研究成果——量子点激光器有望替代目前所有主流激光器供应商(包括Lumentum)使用的量子阱激光器。除了更高的可靠性外,量子点激光器在高温下也表现出更优异的性能,如图所示。
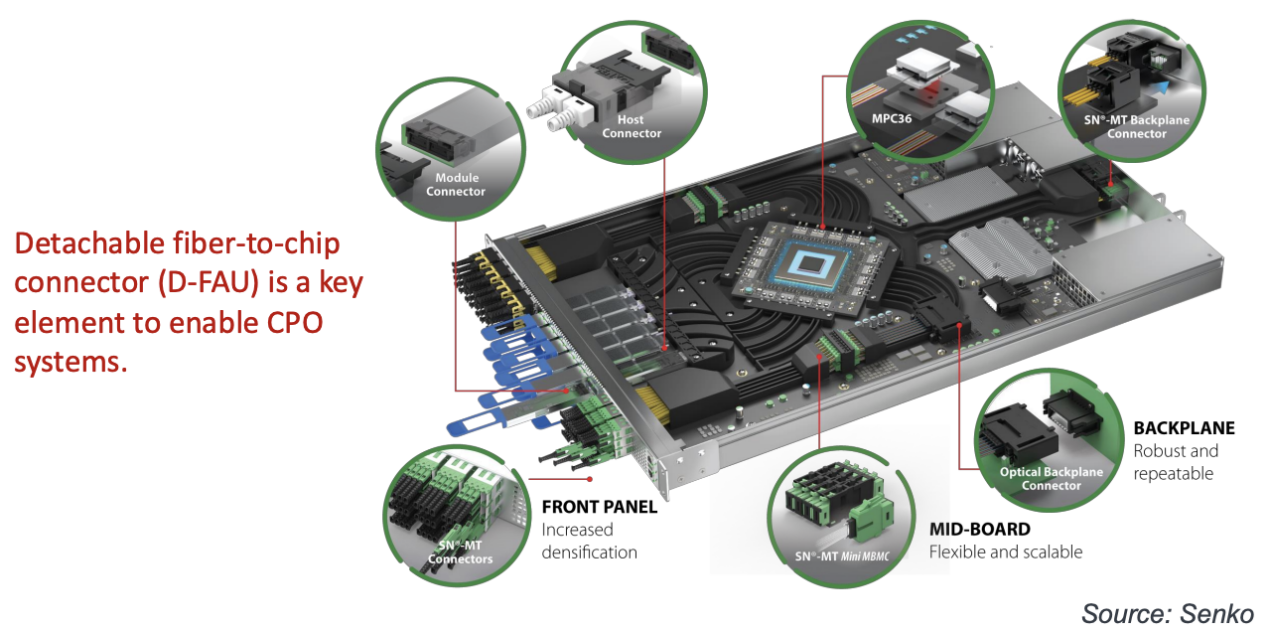
Senko公司的Ryan Vallance讨论了光纤与CPO的连接,下图(上)所示。其中最关键的是可拆卸的光纤芯片连接器,例如MPC36。下图(下)展示了Senko公司采用金属光学平台技术开发的MPC型连接器的设计。
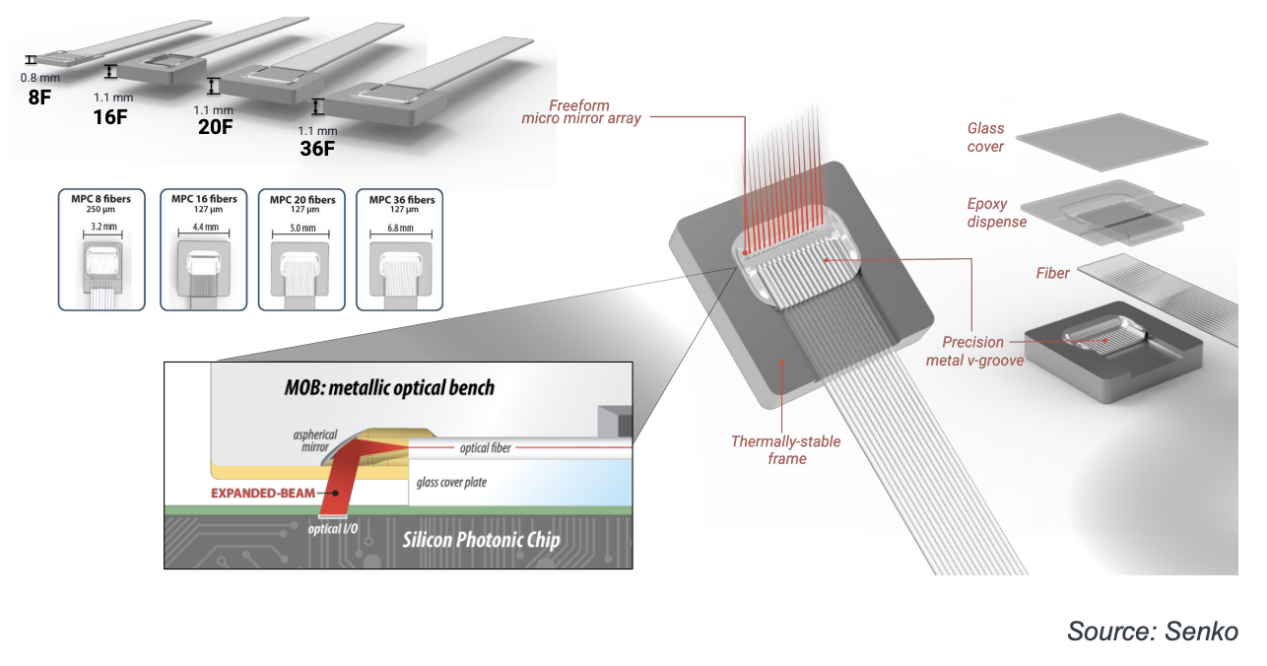
平面光栅垂直耦合技术最早由 Luxtera 公司于十多年前推出。该技术最初由台积电与 Luxtera 合作开发,并被集成到 COUPE 工艺中,此后又被众多合作伙伴采用。它与台积电用于多芯片模块的 CoWoS 工艺兼容。
光栅耦合器的一个重要局限性在于其波长敏感性。它适用于 DR4 型光学元件,但 FR4 光学引擎则采用边缘耦合。
Poet Technologies 公司的 Raju Kankipati 介绍了该公司针对晶圆级集成和封装的解决方案。上图展示了他们采用激光器、透镜、隔离器和光纤阵列进行边缘耦合的方法,以最大限度地减少所需的主动对准步骤。
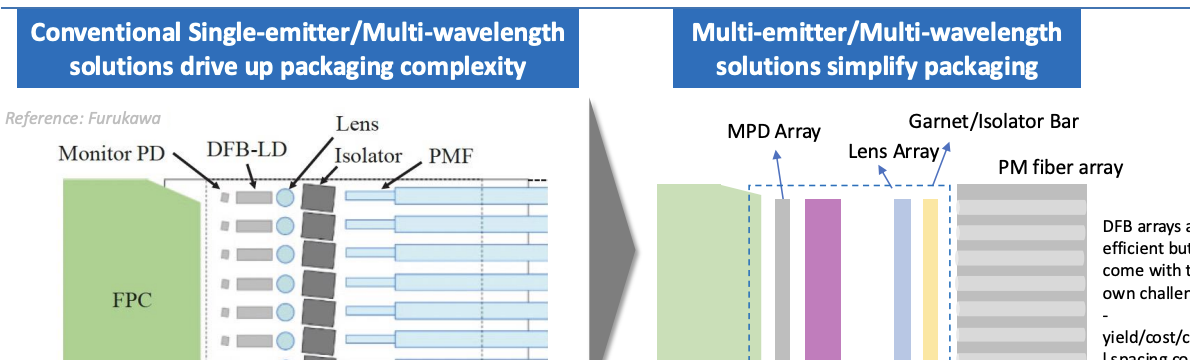
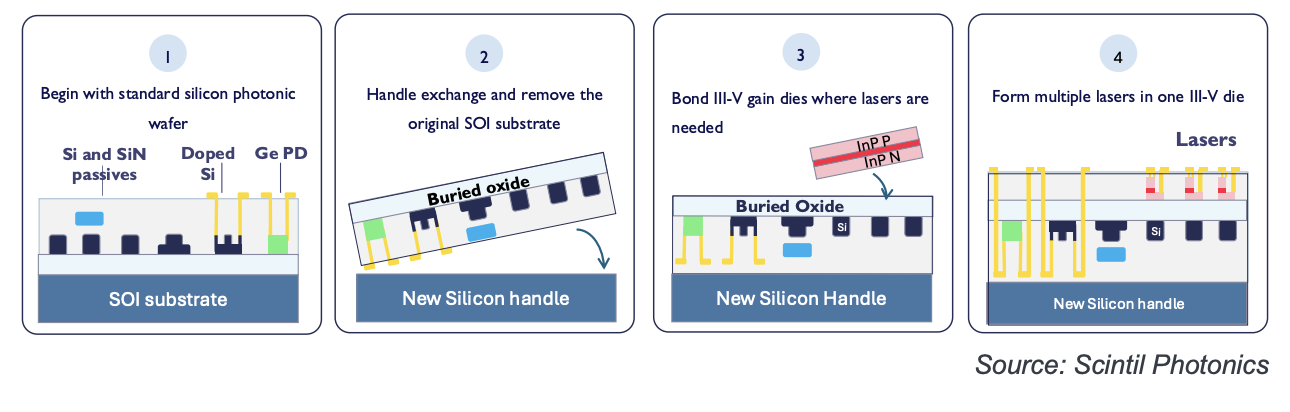
最近加入 Scintil Photonics 的 Jim Theodoras 讨论了该公司在绝缘体上硅 (SOI) 晶圆上异质集成 InP 芯片的独特方法,如下图所示。在该方法实现的各种解决方案中,该公司现在提供用于支持 CPO 的外部激光源的多波长 DFB 激光阵列。
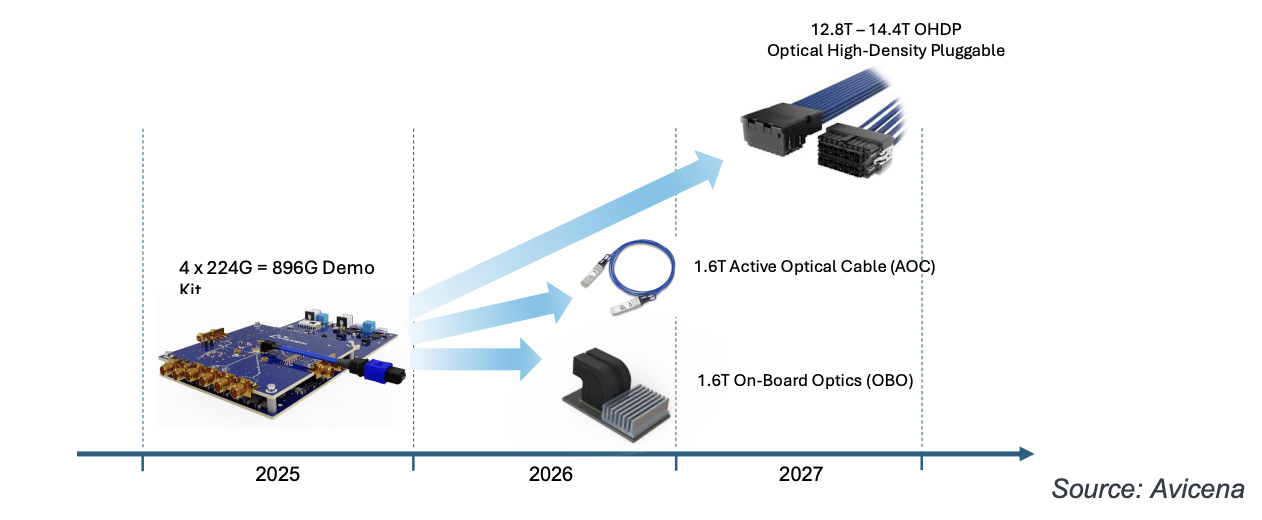
Avicena 公司的 Chris Pfistner 展示了产品路线图,如图所示。该公司的二维微型 LED 阵列可进行调整,以支持高速 AOC、板载和可插拔连接,从而扩展网络规模。这些解决方案需要齿轮箱来复用多个低速(<10Gbps)LED 连接,以实现每车道 200G 的信号传输。尽管齿轮箱需要额外的功率,但 Avicena 的解决方案仍可实现 5pJ/bit 的能效,这得益于超低功耗微型 LED 的消耗。
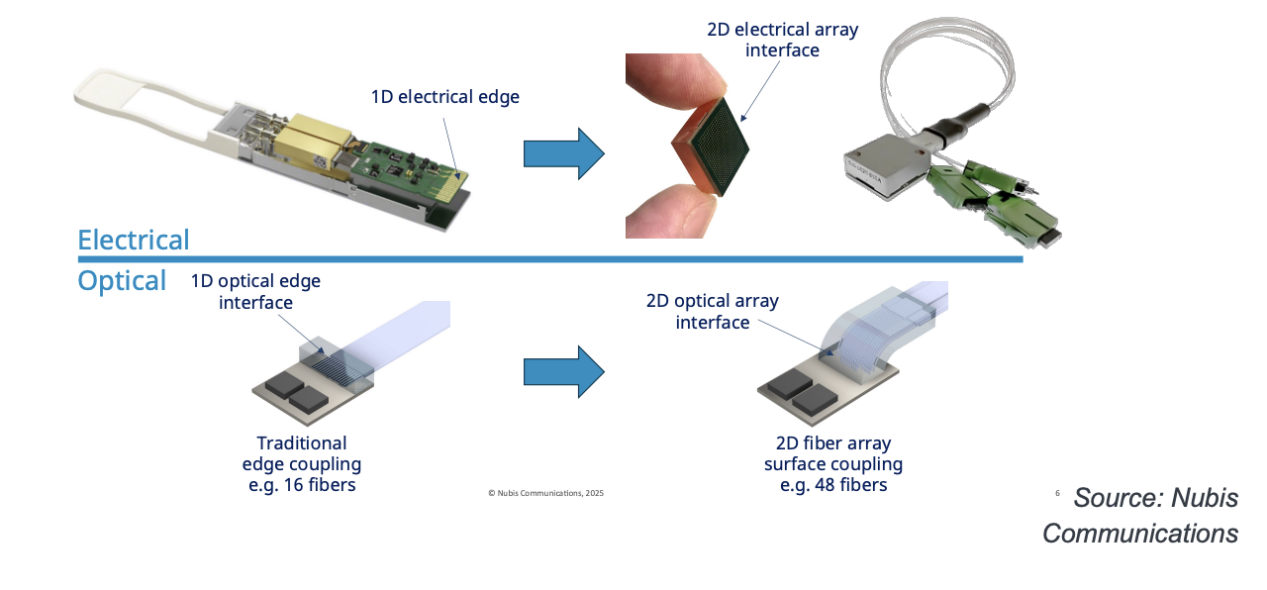
Nubis Communications 开发的产品也采用了二维阵列互连技术,但与 Avicena 的方法不同,这些产品基于高速硅光子技术,无需齿轮箱。图 13 展示了二维阵列电光互连的优势。
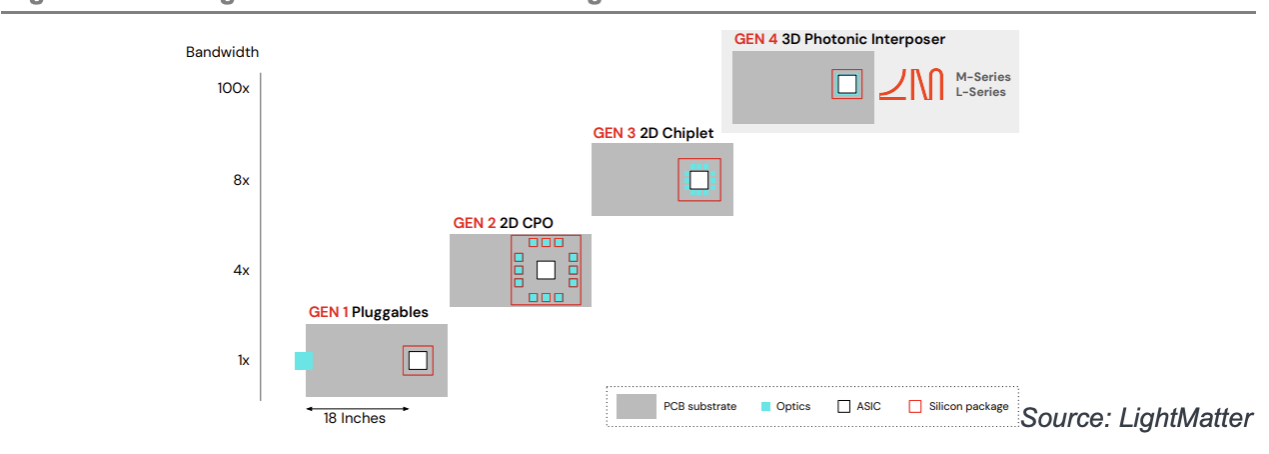
Celestial AI 和 LightMatter 是目前业内最具雄心且资金最雄厚的初创公司。这两家公司都致力于开发更先进的 CPO 技术——远超博通、英伟达和其他新兴供应商目前提供的解决方案(如下图所示的第二代 CPO)。第四代 CPO 并非将光引擎置于 ASIC 周围,而是将光互连置于 ASIC 下方。
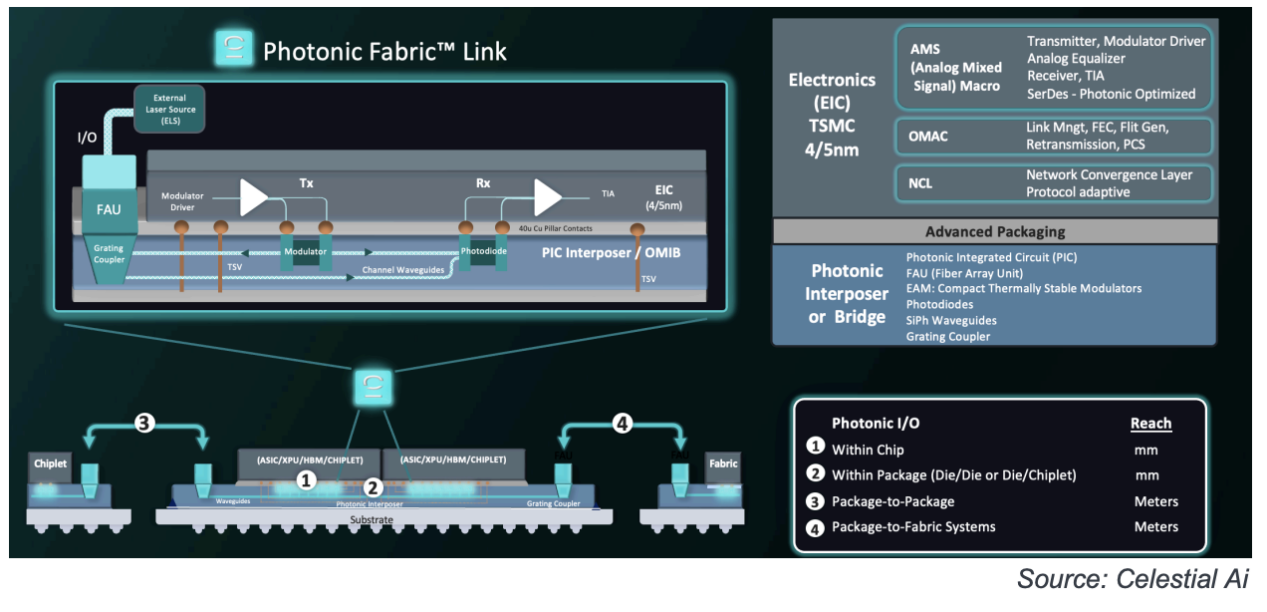
采用这种方法将与目前诸如台积电开发的 CoWoS 等芯片封装技术截然不同。LightCounting 认为,这将是第四代 CPO 普及应用的一大障碍,但趁着投资者愿意投资,尽早开始研发并尽可能多地筹集资金永远不会太早。
上个月,在七月,LightCounting发布了一份关于 Tomahawk 6 的研究报告,指出博通针对 AI 集群扩展互连技术的新定位。然而,一款专为扩展以太网 (SUE) 重新架构的截然不同的交换机却仍处于保密状态。尽管名称不同,Tomahawk Ultra 代表了一种全新的设计,旨在提供更低的延迟和更高的小数据包性能。博通最初启动该设计时,目标是在高性能计算 (HPC) 领域取代 InfiniBand。随着项目的推进,英伟达的 NVLink 扩展互连技术成为了新的目标。
由于开发周期较长,Tomahawk Ultra (TH-U) 与 Tomahawk 5 (TH5) 的相似之处远多于与新款 Tomahawk 6 (TH6) 的相似之处。事实上,博通将 TH-U 设计为与 Tomahawk 5 100% 引脚兼容。TH-U 采用单片式设计,与 TH5 共享相同的 512x100Gbps Peregrine SerDes,并沿用了成熟的 5nm 设计。这使得 TH-U 成为一款 51.2Tbps 的交换机,能够驱动长达 4 米的 DAC 或铜质背板,且插入损耗相当。这也意味着 TH-U 应与通过 TH5 认证的 LPO 模块兼容,并且如果客户需要完整的 CPO 版本,它还可以与 Bailly CPO 引擎结合使用。TH-U 目前正在进行样品测试,预计将于 2026 年上半年投入生产。
为了实现 250ns 的宣称延迟,博通不得不使用比 TH5 更多、更快的包处理流水线。此外,它还必须重新设计其流量管理器和缓冲存储器架构。由于 TH5 已经将光刻技术的尺寸限制在芯片尺寸的极限范围内,TH-U 牺牲了数据包缓冲区的大小,为更多的流水线以及全新的网络内集合 (INC) 引擎腾出空间。因此,在需要更大缓冲区的现有应用中,TH-U 无法取代 TH5。
博通公司明确宣传了TH-U的各项功能,这些功能正是其“扩展以太网”(SUE)规范所必需的。这些功能包括链路层重试(LLR)和基于信用的流量控制(CBFC),它们能够实现类似InfiniBand一贯提供的硬件级可靠性。LLR和CBFC都是上个月发布的Ultra Ethernet Specificationv1.0的可选功能。TH-U还支持一种优化的以太网报头,SUE规范将其称为AI转发报头(AIFH)。AIFH本质上是将标准的IP+UDP报头压缩成一个更小的熵值,而该熵值对于负载均衡仍然至关重要。
TH-U提供最大256个200GbE端口,允许其在单跳中连接多达256个XPU。这仅为TH6最大端口数的一半,而TH6-200G版本还支持两倍的通道速度。不难想象第二代 TH-U 芯片采用 3nm 工艺,搭载 200G SerDes,但这样的芯片不太可能很快面世。与此同时,TH-U 芯片比 NVLink5 落后一代,后者已经实现了 200G/通道的出货速度。
*文章版权归原作者所有,如有不妥,请后台联系删除。





